
目次
はじめに
近年、企業だけでなく個人でも「クラウド」を使うのが当たり前になりました。
特に AWS(Amazon Web Services) は世界中で利用されている代表的なクラウドサービスです。
しかし「仮想化」「分散処理」「スケーリング」といった言葉を聞くと、難しそうで手を出しにくいと感じる人も多いでしょう。
この記事では、クラウドを理解するうえで欠かせない 仮想化と分散処理の基本 を、初心者向けにわかりやすく解説します。
AWSのサービスをイメージしながら読むことで、クラウドの全体像がスッキリ見えるようになりますよ。

仮想化とは
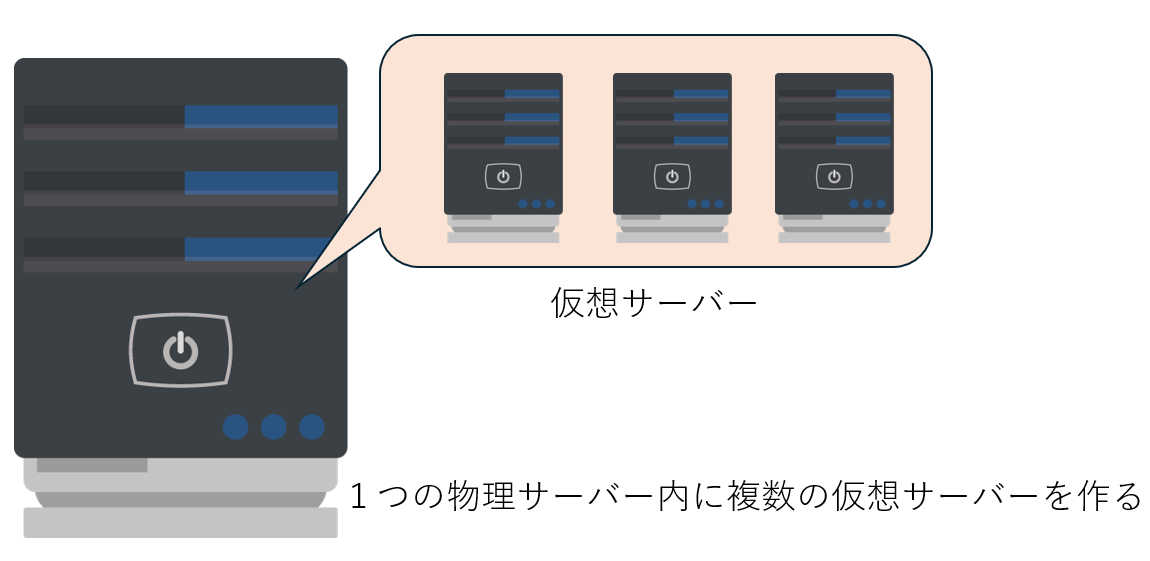
「仮想化」とは、1台の物理的なサーバーをソフトウェアの力で分割し、複数の仮想サーバーとして使えるようにする技術のことです。
例えるなら、大きな家の中に壁を作って部屋を増やし、それぞれを独立して使えるようにするイメージです。
これにより、サーバーの無駄を減らし、効率よく利用できるようになります。
仮想化であっても物理的には存在する
「仮想」と聞くと、まるで実体がないように思えるかもしれません。
しかし仮想サーバーは必ず 物理サーバー の上に成り立っています。
AWSでは巨大なデータセンターに設置された物理サーバーを仮想化して、多数のユーザーが同時に利用できる仕組みを作っています。
物理的なサーバーと仮想的なサーバーの違い
| 項目 | 物理サーバー | 仮想サーバー(AWS EC2 など) |
|---|---|---|
| 実体 | 実際のハードウェア(CPU, メモリ, HDD) | ソフトウェア的に作られた仮想環境 |
| 管理 | 自分で設置・管理・保守が必要 | AWSが物理部分を管理、利用者は仮想環境だけ操作 |
| 柔軟性 | 追加や変更に時間とコストがかかる | 数分で作成・削除が可能 |
| コスト | 初期費用が高い | 使った分だけ課金(従量課金制) |
AWSで学ぶ分散処理とは?初心者でもわかる仕組みと活用例
クラウドサービスを学んでいると、必ず出てくるキーワードのひとつが「分散処理」です。
ただ、名前だけ聞くと「なんだか難しそう…」と感じる方も多いのではないでしょうか?
実は分散処理とは、とても身近な考え方をITに応用したものです。
例えば学校のグループ課題を想像してください。
ひとりでレポートを100ページ書くのは大変ですが、10人で10ページずつ分担すれば、短い時間で仕上げられます。これがまさに「分散処理」です。
この記事では、クラウドサービスの代表格である AWS(Amazon Web Services) を例に、分散処理の仕組みや必要性、代表的なサービス、メリット・デメリットまで初心者向けに解説します。
1. 分散処理とは?基本の考え方
分散処理とは、ひとつの大きな仕事を小さな単位に分割し、複数のサーバーで同時に処理する仕組み です。
具体例で考える
- 本の要約:1人で1000ページの本を要約するより、10人で100ページずつ担当した方が速い
- 料理の仕込み:カレーをひとりで作るより、具材を切る人・煮込む人・盛り付ける人に分担した方が効率的
- 荷物の仕分け:ひとりで段ボール100個を分けるより、5人で20個ずつ仕分けした方が早い
このように「同時並行で作業を進める」ことが、分散処理の最大の特徴です。
2. 分散処理が必要になるシーン
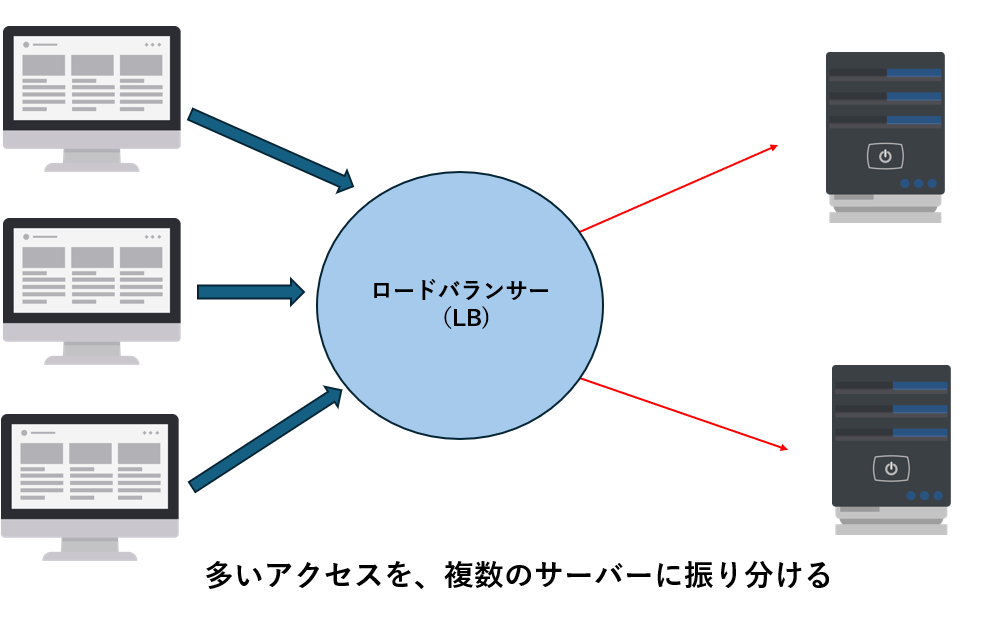
- アクセスが集中するWebサービス
ECサイトのセール中。大量のリクエストが同時に押し寄せても、複数のサーバーで処理を分け合えば、サイトが落ちにくくなります。 - ビッグデータ解析
SNSの投稿やIoTセンサーからのデータなど、膨大な情報を短時間で処理可能。 - AI・機械学習のトレーニング
学習処理を並列化し、数週間かかる計算を数日で完了できるケースもあります。 - 動画配信サービスの変換処理
動画を複数の画質・形式に同時変換する処理でも分散処理は活躍。
3. AWSにおける分散処理の主なサービス
AWSには分散処理をサポートする仕組みが豊富に揃っています。
サービス比較表
| サービス名 | 主な用途 | 特徴 | 初心者向け度 |
|---|---|---|---|
| Amazon EMR | ビッグデータ解析、ログ処理 | Hadoop/Sparkを簡単に利用可能 | 中級〜上級 |
| Amazon Aurora | データベース処理 | 高速な読み取り分散、スケール可能 | 初級〜中級 |
| AWS Lambda + SQS/SNS | イベント駆動の並列処理 | サーバーレスで小規模処理を並列実行 | 初級 |
| ECS/EKS | コンテナ・マイクロサービス | 大規模アプリを分散して実行可能 | 中級〜上級 |
4. 分散処理の仕組みを理解する3ステップ
- タスクを分割する
例:1000件の処理を100件ずつに分ける。 - サーバーに割り当てる
例:AWSのEC2インスタンスやLambdaに処理を振り分ける。 - 結果を統合する
例:分割した処理の結果をひとつにまとめ、ユーザーに返す。
この流れを自動化してくれるのがAWSの強みです。
5. 分散処理のメリットとデメリット
メリットとデメリット比較表
| 項目 | メリット | デメリット |
|---|---|---|
| 処理速度 | 複数サーバーで同時実行でき高速化 | 設計が複雑になりやすい |
| 信頼性 | 一部サーバーが落ちても他がカバー | ネットワーク遅延の影響を受ける |
| スケーラビリティ | 利用状況に応じて拡張可能 | サーバー数が増えるとコスト増 |
6. AWSで分散処理を試すなら
- AWS Lambdaで並列処理を体験:複数ファイルを同時処理して並列化を理解
- Amazon Athena + S3でデータ分析:保存したCSVやログを高速クエリ
- Amazon EMRでログ解析:Hadoop/Sparkを使った大規模データ分析に挑戦
分散処理のまとめ
分散処理は、クラウドを支える重要な仕組みです。
- 大きな処理を小さく分割して並列実行する
- ECサイト、ビッグデータ、AI、動画処理などで活躍
- AWSにはEMR・Aurora・Lambda・ECS/EKSなど多彩なサービスがある
- メリットとデメリットを理解し、段階的に導入することが大切
まずは AWS LambdaやAthenaで小規模な分散処理を体験 し、仕組みに慣れることをおすすめします。
そこからステップアップすれば、AWSを効率的かつ信頼性の高いプラットフォームとして活用できるようになります。
レプリケーションとは?クラウドを守るデータのコピー術

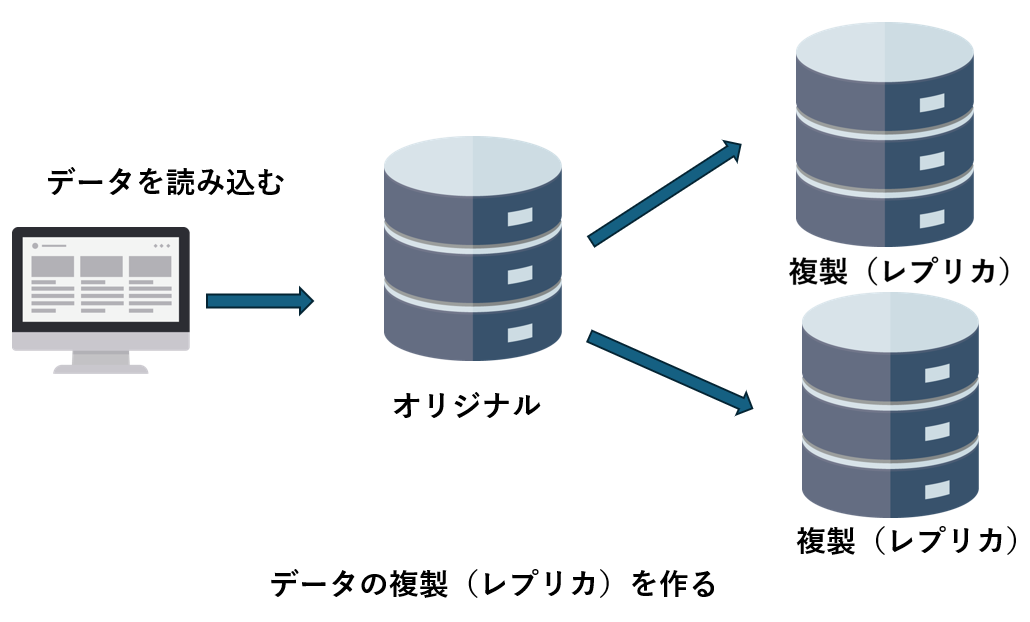
「レプリケーション」とは、データを複製して複数のサーバーや拠点に保存する仕組み のことです。
1台のサーバーだけにデータを保存していると、そのサーバーが壊れたり停電が起きたりしたときに、データがすべて失われてしまうリスクがあります。
そこで、あらかじめ複製(コピー)を作って別のサーバーやデータセンターに置いておけば、万が一のときでも復旧できます。
日常の例で考える
- ノートのコピー:授業のノートを1冊しか持っていないと失くしたとき困りますが、コピーを友達に渡しておけば安心。
- クラウド保存:スマホの写真を本体だけでなくiCloudやGoogleフォトにも保存しておけば、端末が壊れても復元可能。
- 銀行口座:1つの口座に全財産を入れておくより、複数の口座に分散しておく方がリスク分散になる。
これらはすべて「レプリケーション」と同じ考え方です。
AWSにおけるレプリケーションの仕組み
AWSでは、データを リージョン(地域) や アベイラビリティゾーン(複数のデータセンター群) に複製して保存できます。
- Amazon S3:標準で3つ以上のアベイラビリティゾーンに自動レプリケーション
- Amazon RDS:マルチAZ配置により、データベースのコピーを別のゾーンに待機させる
- Amazon DynamoDB:グローバルテーブル機能を使えば、世界中のリージョンにデータを複製可能
レプリケーションの種類
| 種類 | 特徴 | AWSでの例 |
|---|---|---|
| 同期レプリケーション | データを保存すると同時にコピーも作成。常に同じ状態を保つ。 | RDS マルチAZ配置 |
| 非同期レプリケーション | 少し遅れてコピーを作成。速度は速いが、障害時に一部データが失われる可能性。 | S3 クロスリージョンレプリケーション |
| 地理的レプリケーション | 複数の地域にデータをコピー。災害や大規模障害に強い。 | DynamoDB グローバルテーブル |
レプリケーションのメリットとデメリット
| 項目 | メリット | デメリット |
|---|---|---|
| 耐障害性 | サーバー障害時でもデータを復旧できる | コピー先も障害があると完全保証ではない |
| 可用性 | 常に利用できる状態を維持できる | 運用コストが高くなることがある |
| グローバル展開 | 世界中で高速アクセス可能 | 地理的レプリケーションは設計が複雑 |
イメージしやすいAWSでの例
- S3を使った自動レプリケーション:S3は保存した瞬間から複数のゾーンにコピーされるため「消えないストレージ」と呼ばれることもあります。
- RDSのマルチAZ構成:データベースを2つ以上のゾーンに配置しておき、片方が落ちてももう片方がすぐに切り替わる。
- DynamoDBのグローバルテーブル:東京リージョンで保存したデータが、すぐにアメリカやヨーロッパのリージョンでも利用できる。
レプリケーションのまとめ
「レプリケーション」とは、大事なデータをコピーして守る仕組み です。
- 同期・非同期・地理的レプリケーションの種類がある
- AWSではS3、RDS、DynamoDBなどが自動的に対応
- 耐障害性・可用性・グローバル展開を実現できる反面、コストや設計の複雑さに注意
初心者の方も、まずは S3の仕組みが「デフォルトでレプリケーションされている」 ことを知るとイメージが湧きやすいでしょう。
AWSを使ううえで「レプリケーションは空気のように当たり前に動いている仕組み」なのです。
スケーリングとは?システムを柔軟に拡張する仕組み
AWSの魅力のひとつが スケーリング です。
これは、システムの利用状況に応じてサーバーの数や性能を調整する仕組みを指します。
アクセスが少ないときは無駄を省き、多いときは自動で強化することで、コストを抑えつつ安定した動作を維持できます。
スケーリングの種類
| 種類 | 方法 | 文言 | イメージ | メリット |
|---|---|---|---|---|
| スケールアップ / スケールダウン | 1台のサーバーの性能(CPUやメモリ)を増強 or 減らす | アップ=強化 ダウン=縮小 | PCにメモリを増設して処理速度を上げる or 外して省エネ | サーバー数はそのままなので管理が簡単 |
| スケールアウト / スケールイン | サーバー台数を増やす or 減らす | アウト=拡張 イン=縮小 | レストランで混雑時にスタッフを増やす or 落ち着いたら減らす | 大量アクセスにも対応可能、柔軟性が高い |
AWS Auto Scalingでできること
AWSには Auto Scaling という機能があり、アクセス数や負荷に応じて自動的にサーバー数を増減できます。
- 深夜のアクセスが少ないとき → スケールイン / ダウン でコスト削減
- 昼間やセール時にアクセス急増 → スケールアウト / アップ で安定稼働
これにより、利用者は常に快適にサービスを使え、運営側も「使った分だけのコスト」で効率的にシステムを運用できます。

冗長化とは?システムを止めないための仕組み
「冗長化」とは、障害が発生してもサービスを継続できるように、あらかじめ複数のサーバーやネットワーク機器を用意しておく仕組み のことです。
もし1台のサーバーだけに依存していたら、そのサーバーが壊れた瞬間にサービスは停止してしまいます。
ですが冗長化しておけば、別のサーバーや機器がすぐに引き継ぎ、利用者はほとんど影響を感じずにサービスを使い続けられます。
日常生活の例で考える
- 電車の複数路線:1路線が事故で止まっても、他の路線で目的地に行ける。
- バックアップ電源:停電しても非常用発電機が動いて照明が消えない。
- 二人三脚のチーム:片方が疲れても、もう片方がカバーする。
冗長化は「万が一」に備えた安心の仕組みです。
冗長化の方式まとめ
| 種類 | 内容 | AWSでの例 | メリット | 注意点 |
|---|---|---|---|---|
| サーバー冗長化 | 複数のサーバーを用意し、障害時に切り替える | EC2 Auto Scaling、ELB(ロードバランサー) | 障害時でもサービスを継続可能 | サーバー数が増える分コスト増 |
| データ冗長化 | データを複数の場所に保存 | S3は標準で3つ以上のAZに保存 | データ消失リスクを最小化 | 完全なリアルタイム同期にはコスト |
| ネットワーク冗長化 | 複数の回線・ルーターを用意 | Direct Connect + VPN併用 | 通信経路の障害に強い | 設計が複雑 |
| ゾーン/リージョン冗長化 | 複数のAZやリージョンにシステムを分散 | RDSマルチAZ、DynamoDBグローバルテーブル | 災害にも強い | 運用設計が難しい |
AWSで実現できる冗長化の代表例
- Amazon S3:同じデータを自動的に複数のアベイラビリティゾーンに保存
- Amazon RDS(マルチAZ配置):メインDBが停止してもスタンバイDBに自動切り替え
- Elastic Load Balancing (ELB):複数サーバーにトラフィックを分散、障害時は正常なサーバーへ振り分け
冗長化のまとめ
冗長化は、「壊れても止まらない仕組み」 を作ることです。
- サーバー・データ・ネットワーク・ゾーンそれぞれに冗長化の考え方がある
- AWSはS3やRDS、ELBなどで標準的に冗長化をサポート
- コストや設計の複雑さはあるが、サービス継続性を守るために欠かせない
「S3のデータは最初から冗長化されている」という事実を知るとイメージが掴みやすいです。
AWSを利用する大きな安心材料ですね。
バックアップとは?大切なデータを守る最後の砦
最後に重要なのが バックアップ です。
バックアップとは、障害や誤操作に備えてデータをコピーし、安全な場所に保存しておく仕組み のことです。
たとえば、スマホの写真をうっかり削除してしまった経験はありませんか?
バックアップを取っていれば、別の場所から復元できて「失われた」と思ったデータを取り戻せます。
これがバックアップの役割です。
日常生活の例で考える
- USBやクラウド保存:PCに保存した資料を、Google DriveやUSBにも保存しておけば復旧可能。
- 家の合鍵:玄関の鍵をなくしても、予備の合鍵を持っていれば安心。
- アルバムのコピー:結婚式の写真をアルバムだけでなくデジタルデータでも保存しておく。
どれも「万一」に備えるという意味で、バックアップと同じ考え方です。
バックアップとレプリケーションの違い
| 項目 | バックアップ | レプリケーション |
|---|---|---|
| 目的 | データのコピーを残して復元する | データを複数の場所にリアルタイム複製 |
| 保存場所 | オンプレ・クラウド・外部ストレージなど | 主にサーバーやクラウドの複数拠点 |
| タイミング | 定期的(毎日・毎週など) | 常時 or 遅延付き同期 |
| 復旧方法 | 過去のコピーから復元可能 | 障害時にすぐに切り替え可能 |
👉 ポイント
- バックアップは「過去に戻れる仕組み」
- レプリケーションは「止まらない仕組み」
AWSで利用できるバックアップサービス
- Amazon S3
- 高耐久のストレージにデータを保存
- バージョニング機能で「古いバージョン」も保持可能
- AWS Backup
- EC2、RDS、EFS、DynamoDB などのデータを一元的にバックアップ
- 世代管理や自動スケジューリングに対応
- Glacier (S3 Glacier)
- 長期保存用の低コストストレージ
- 滅多に使わないが大事なデータを数年単位で保管可能
バックアップの種類
| 種類 | 特徴 | AWSでの例 | メリット | 注意点 |
|---|---|---|---|---|
| フルバックアップ | すべてのデータをコピー | S3に全データ保存 | 復旧が簡単で確実 | 保存容量が大きくなる |
| 差分バックアップ | 前回フルバックアップからの差分を保存 | AWS Backupのスケジュール | 容量を削減可能 | 復元時にフル+差分が必要 |
| 増分バックアップ | 直近のバックアップとの差分を保存 | S3バージョニングと連携 | 容量を最小化 | 復元に時間がかかる |
バックアップのまとめ
バックアップは、「もしもの時に過去へ戻れる仕組み」 です。
- 誤操作・障害・災害に備えて安全な場所にコピーを保存
- AWSでは S3・AWS Backup・S3 Glacier などが利用可能
- フル・差分・増分など用途に応じた方式を選べる
- レプリケーションと組み合わせると、さらに堅牢なシステムを構築できる
まとめ
AWSの仕組みを理解するには、まず「仮想化」と「分散処理」を押さえることが大切です。
- 仮想化:物理サーバーを効率よく分けて使う技術
- 分散処理:複数サーバーで同時に作業を分け合う仕組み
- レプリケーション、スケーリング、冗長化、バックアップ:信頼性と柔軟性を高める仕掛け
これらを知っておくと、クラウドを「ただ便利なもの」として使うのではなく、裏側の仕組みを理解しながら活用できるようになります。初心者の方も、まずはこの基本を押さえて、AWSを使いこなす一歩を踏み出しましょう!



